ANS:
Adaptive Noise Shaping
MPEGplus
gehört zu der Gruppe der Teilband-Coder. Er zerlegt also das breitbandige
Audiosignal in mehrere (32) Teilbänder und quantisiert diese mit unterschiedlichen
Auflösungsstufen. Im Gegensatz zu den T/F-Codern werden bei Teilband-Codern
noch Zeitsignale quantisiert, wodurch sich die Möglichkeit des Noise
Shaping erschließt.
Ein Problem bei einem Teilband-Coder mit
konstanter Subbandbandbreite (hier 689 Hz) ist die geringe Frequenzauflösung
des Quantisierungsprozesses bei niedrigen Frequenzen. Das menschliche Gehör
und somit das psychoakustische Modell liefern in den unteren Subbändern
eine wesentlich höhere Frequenzauflösung der erlaubten Verzerrungen
als die Bandbreite der Subbänder. Bei einer gleichförmigen Quantisierung
wird den Teilbändern jedoch im gesamten Spektrum dieselbe Rauschenergie
(weißes Rauschen) hinzugefügt, so daß bei der Quantisierung
immer die im Subband geringste erlaubte Verzerrung als Maß verwendet
werden muß. Gerade im ersten Subband verschenkt man hierdurch Bitrate,
da in diesem meistens die Ruhehörschwelle (zu tiefen Frequenzen stark
steigend) die Maskierung und somit die Mithörschwelle dominiert.
ANS wertet in allen Subbändern
pro Frame die spektrale Formung der Mithörschwelle aus und versucht
ein stabiles, minimalphasiges Noise Shaping-Filter auszulegen. Das Filter
besteht aus einem FIR-Filter von maximal 5. Ordnung, welches den Quantisierungsfehler
negativ zurückführt. Vor dem eigentlichen Noise Shaping werden
die berechneten Filter (Ordnung 1 bis 5) hinsichtlich des zu erwartenden
Gewinns durch die Formung des Quantisierungsrauschens ausgewertet, wobei
dasjenige Filter mit dem höchsten Gewinn für die Rauschformung
verwendet wird. Die Kenntnis über den Gewinn ermöglicht bei einigen
Subbändern die Reduzierung der verwendeten Quantisierungsstufen, wodurch
sich ein realer Gewinn an Bitrate einstellt.
Im ersten Subband, welches aufgrund der
Ruhehörschwelle die stärkste spektrale Formung aufweist, kann
man einen durchschnittlichen Gewinn von etwa 3 dB beobachten, im Mittel
über alle Subbänder etwa 0,2 - 0,9 dB, wodurch rein rechnerisch
eine Ersparnis von 2 - 10 kbit/s erreicht wird. I.A. läßt sich
der Bitaufwand aber kaum reduzieren (typischer Gewinn etwa 5 kbit/s), weil
die erreichten Gewinne zu gering sind, um die Bitzuweisung zu beeinflußen.
Vielmehr erreicht
ANS durch "Anschmiegen" des Rauschspektrums an
die Mithörschwelle eine höhere subjektive Klangqualität.
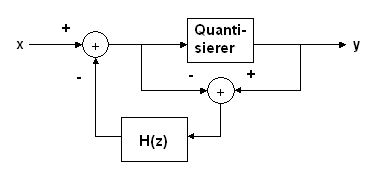
(Blockschaltbild des Noise Shapers)
Für die negative Rückführung
des Quantisierungsfehlers gilt:
Y(z) = X(z) + Q(z) -
Q(z-1) * H(z) = X(z) + Q'(z)
Das Signal X(z) wird also durch die Rückführung
nicht beeinflußt. Das Quantisierungsrauschen erfährt jedoch
eine spektrale Formung nach:
Q'(z) = Q(z) * ( 1-H(z)
), mit Q(z) als weißem Rauschen eines gleichförmigen Quantisierers
H(z) muß also so ausgelegt werden,
daß 1-H(z) dem gewünschten Rauschspektrum entspricht. Um H(z)
zu berechnen, kann man sehr leicht einen Vergleich zur linearen Prädiktion
ziehen. Bei der linearen Prädiktion wird aus einem Eingangssignal
X(z) durch ein FIR-Filter H(z) ein Schätzwert Y(z) so berechnet, daß
der Schätzfehler Q(z) = X(z) - Y(z) = X(z) * (1-H(z)) möglichst
zu einem weißen Rauschen wird. Der Prädiktor "entfärbt"
also das Eingangsspektrum, während der Noise Shaper ein weißes
Rauschen färben soll. Beide Verfahren haben jedoch dieselbe
Übertragungsfunktion.
Man kann also ein Prädiktorfilter
H(z) auslegen, welches als Eingangssignal das invertierte gewünschte
Rauschspektrum hat. Wenn dieses FIR-Filter H(z) in den Noise Shaper eingebaut
wird, erfolgt genau die spektrale Formung des Rauschens, die erzielt werden
sollte.
Die Vorgehensweise zur Berechnung von
H(z) ist wie folgt:
-
invertiere Q_desired(z):
Q_desired_inv(z) = 1/ Q_desired(z); Q_desired(z)
sei die abgetastete Mithörschwelle
-
berechne die Autokorrelationsfunktion von
|Q_desired_inv(z)|² mittels inverser Fouriertransformation:
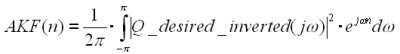
-
für ein optimales Prädiktorfilter
(hier 3.Ordnung) muß gelten:
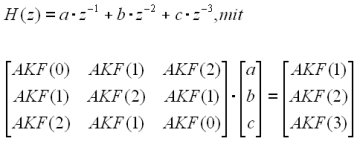
Nach Lösen des Gleichungssystems (z.B.
mittels des Durbin-Algorithmus) kann das FIR-Filter H(z) zur Rauschformung
verwendet werden.
Abbildung 1 und 2 zeigen ein Beispiel für
das Leistungsdichtespektrum des Codierungsfehlers einer gleichförmigen
und einer spektral geformten Quantisierung. Die roten Linien im Bild
stellen in etwa die Grenzen der Subbänder dar. Besonders im ersten
und zweiten Subband ist die spektrale Formung des Quantisierungsrauschens
gut erkennbar. Im ersten Subband wird das Rauschspektrum an die Ruhehörschwelle
angepaßt, wodurch mehr Rauschen im unteren Frequenzbereich liegt
und der Bereich um ca. 400 Hz etwa 3 dB weniger Rauschleistung aufweist.
Im zweiten Subband wurde das Rauschen um ca. 700 Hz erhöht wodurch
Bitrate eingespart wird. Die spektrale Formung an den Rändern der
Subbänder ist im Aliasing begründet, welches höhere Rauschpegel
benachbarter Subbänder in die jeweiligen Subbänder "verschmiert".
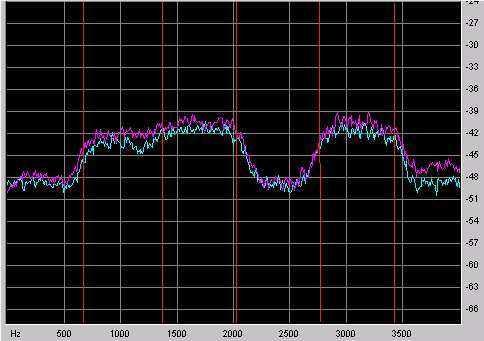
Abb.1: gleichförmiger Quantisierer
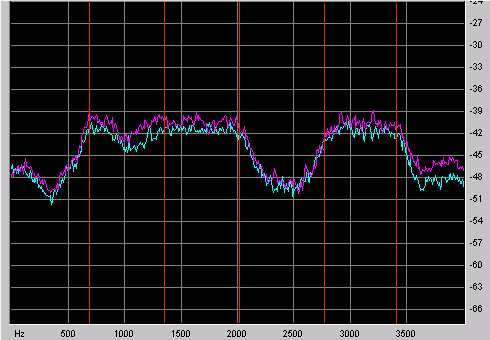
Abb.2: Noise Shaping
CVD:
Clear Voice Detection
Das psychoakustische Modell beschreibt
wieviel Verzerrung dem Audiosignal bei welcher Frequenz hinzugefügt
werden darf, sodaß diese gerade nicht wahrnehmbar sind. Hierbei muß
zwischen tonalen (sinusartigen) Signalen und rauschartigen unterschieden
werden, weil sinusartige Signale eine geringere Verzerrung erlauben als
rauschartige. Im Modell ist dies durch eine Prädiktion der Amplitude
und Phase jeder Spektrallinie realisiert, deren Übereinstimmung mit
den wirklichen Größen ein Maß für die "Tonalität"
dieser Spektrallinie ist.
Leider treffen in der Praxis zwei Dinge
aufeinander: zum einen nimmt das menschliche Gehör Verzerrungen bei
menschlichen Stimmen besonders leicht war, zum anderen erkennt das psychoakustische
Modell gerade solche Signal nicht eindeutig, da sich oft die Grundharmonischen
während des Sprechens schnell um mehrere Prozent bzw. Hz ändern.
Der Prädiktor des Gehör-Modells macht folglich Fehlschätzungen
und läßt zu starke Verzerrungen zu.
CVD greift zur Vermeidung solcher
Effekte auf eine andere Methode zur Erkennung von harmonischen Spektren
zurück. Die kritischsten Signale sind gesprochene oder gesungene Vokallaute,
welche eine stark harmonische Struktur aufweisen. Aus der Sprachcodierung
und -erkennung ist das Cepstrum bekannt, in dem sich bei harmonischen Spektren
äquidistante Diracstoßfolgen erkennen lassen. Der Abstand dieser
Impulse kennzeichnet hierbei die Grundfrequenz.
Im MPEGplus-Coder wird zweimal
je Frame das Cepstrum des Audiosignals berechnet. Hierzu werden die Leistungsdichtespektren
einer 1024er-FFT tiefpaßgefiltert (von 5,5 kHz bis 11 kHz mittels
cos-roll-off), da die hohen Frequenzanteile keine nennenswerte Information
mehr über stimmhafte Signale enthalten und sie daher die Analyse eher
stören würden. Der sanfte Tiefpaß dient dazu, die Diracstöße
im Cepstrum möglichst nicht zu "verschleifen". Weist das Cepstrum
einen signifikanten (s.u.) Peak auf, werden alle Obertöne der zugehörigen
Grundfrequenz bis einschließlich 4,3 kHz als sinusartig angenommen
und bekommen sinusoiden Charakter zugewiesen. Durch diese Vorgehensweise
ist es möglich, auch variierende Grundharmonische zu erfassen und
als tonal zu erkennen.
Ein weiterer Vorteil ist, daß signifikante
(bzw. hinreichend hohe) Peaks im Cepstrum nur dann auftreten, wenn das
harmonische Spektrum relativ frei von Rauschen zwischen den Obertönen
ist. Falls also ein harmonischer Klang sowieso durch Rauschen oder andere
Geräusche "verunreinigt" ist, werden keine zu hohen Signalrauschabstände
gefordert. CVD sorgt vielmehr dafür, daß klare harmonische
Klänge - und damit auch Vokallaute - vom psychoakustischen Modell
auch wie solche behandelt werden.
Mit CVD codierte Audiosignale weisen
deutlich weniger "Phantomsprechen" auf als Audiosignale, die nur die normale
Psychoakustik benutzen. Der zusätzliche Overhead liegt je nach Struktur
des Audiosignals bei 2 - 10 kbit/s.
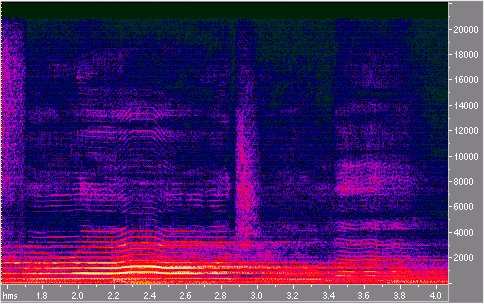
Abb.3: Sichtbare harmonische Struktur eines Vokals
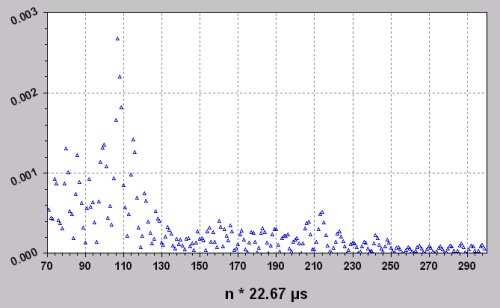
Abb.4: Modifiziertes Cepstrum des Signals aus Abb.3 bei 2,3 s
Zeitvariante Nachmaskierung
Die auf der Audiocoderseite beschriebenen
zeitlichen Maskierungseffekte müssen im Fall der Vormaskierung
(Preecho-Kontrolle) und können im Fall der Nachmaskierung im
psychoakustischen Modell berücksichtigt werden. Im MPEGplus-Encoder
wird hierbei zur weiteren Redundanzreduzierung die Nachmaskierung, welche
einen hochgradig nichtlinearen Vorgang darstellt, in jedem Frame und für
jede Spektrallinie abgeschätzt.
Im Allgemeinen fällt nach einem Schallereignis,
welches eine simultane Maskierungsschwelle zur Folge hat, diese Maskierungsschwelle
innerhalb eines bestimmten Zeitraums wieder auf die Ruhehörschwelle
ab. Das Gehör benötigt also eine gewisse Zeit, um sich wieder
in den "Ruhezustand" vor dem Schallereignis zurückzubringen. Dieser
Zeitraum hängt jedoch von der Dauer des vorangegangenen Schallereignisses
in der Art ab, daß ein langanhaltendes Schallereignis eine lange
und ein kurzes Schallereignis eine kurze "Erholungszeit" des Gehörs
zur Folge hat. Wählt man eine feste Zeitkonstante für die Nachmaskierung,
muß die kürzestmögliche benutzt werden, um bei kurzen Schallereignissen
keine zu lange Maskierung anzunehmen. Dies führt aber nach langanhaltenden
Schallereignissen zu Verlust an Bitrate.
Um diese Verluste zu vermeiden, wird im
MPEGplus-Coder
mittels einer Kurzzeit- und einer Langzeitintegration der simultanen Maskierungsschwellen
mit anschließender Quotientenbildung ein Maß für die Dauer
des vorangegangenen Schallereignisses berechnet. Dieses Maß dient
zur Abschätzung der Zeitkonstanten, mit der die Nachmaskierung berechnet
wird. Gegenüber der Annahme der kürzestmöglichen Nachmaskierung
können sich Gewinne bis zu 8 kbit/s bei gleicher hörbarer Qualität
ergeben.
Die nachfolgenden Messungen zeigen das
Verhalten des psychoakustischen Modells des MPEGplus-Coders.
In den ersten beiden Abbildungen ist deutlich zu erkennen, daß die
Nachmaskierung (rosa) nach den Schallereignissen wieder auf die Ruhehörschwelle
zurücksinkt und währenddessen die Maskierung dominieren kann
(hellblaue Bereiche). Weiterhin werden die unterschiedlichen Zeitkonstanten
erkennbar (lang: ca. 65 ms, kurz: ca. 22 ms).
Die dritte Graphik zeigt den Verlauf der
Nachmaskierungsschwellen für verschiedene vorhergegangene Schallereignisdauern,
wobei 26,1 ms in etwa der Dauer eines Frames entsprechen.
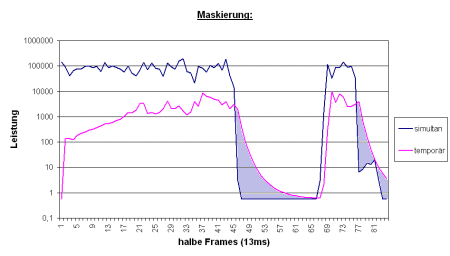
Abb.5: Simultane und temporale Maskierung für lange Schallereignisse
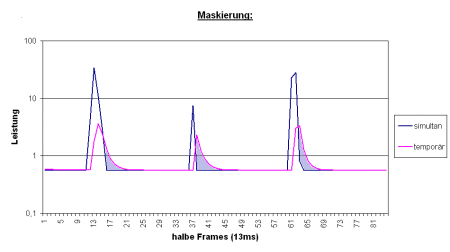
Abb.6: Simultane und temporale Maskierung für kurze Schallereignisse
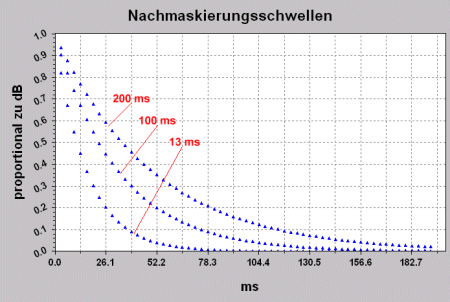
Abb.7: Nachmaskierung für verschiedene Schallereignisdauern